
ウェブサイトの情報を取得する方法のメモです。
魚拓を取る
ウェブサイトの取得は
- 現在アクセス可能なウェブサイトの取得
- サービスを終了したウェブサイトの取得
現在アクセス可能なウェブサイトの情報を取得する
ウェブ魚拓
archive.today
archive.md
archive.md allows you to create a copy of a webpage that will always be up even if the original link is down
archive.md
サービスを終了したウェブサイトの情報を取得する
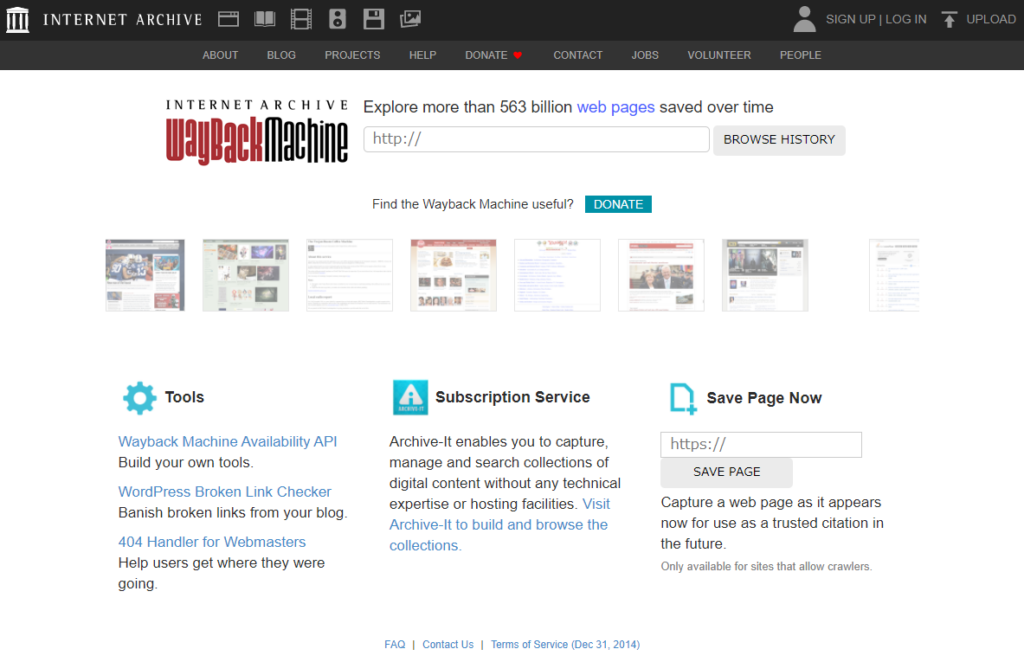
WayBackMachine
過去のウェブサイト取得する場合に重宝します。

404 Not Found
archive.org
参考
- ウェブ魚拓、出典: フリー百科事典『ウィキペディア(Wikipedia)』、2021年5月閲覧

共有コメント 共有されるコメント欄です。